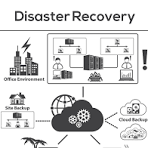
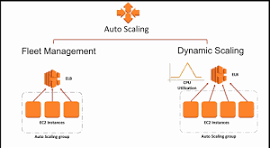
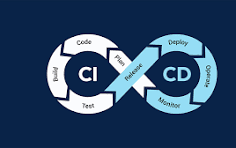
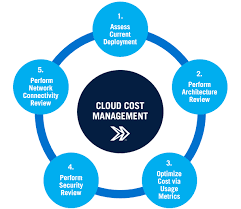
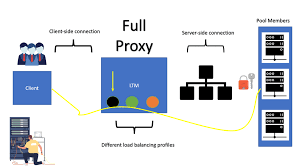
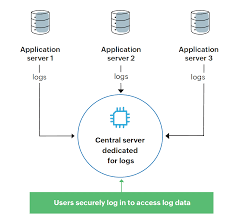
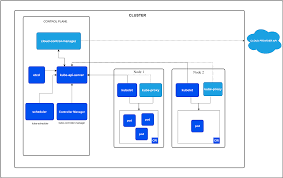
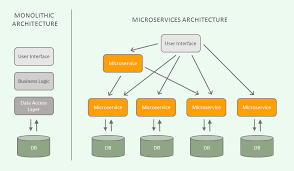
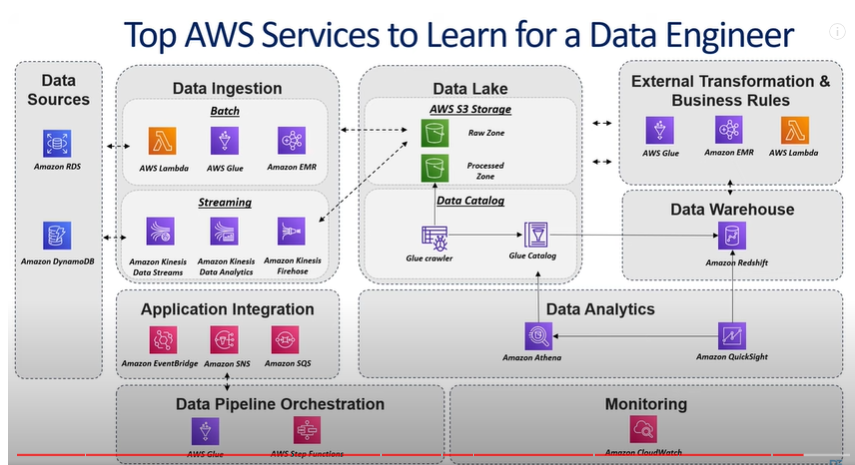
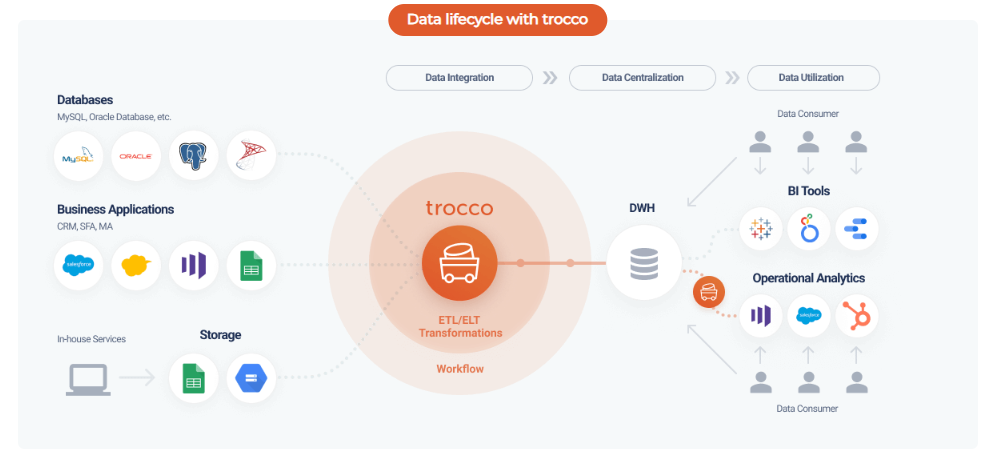
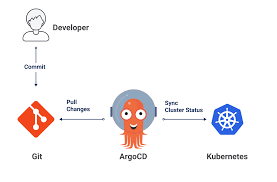
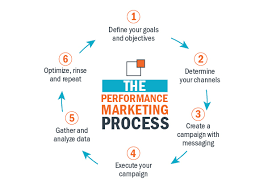
Knowledge Power Solution is a one-stop solution for those who are going to dive into the IT Industry we also serve live training on projects for hands-on experience for students and professionals, we are working with people to the enrichment of each other technical skills through shared experience come with the daily technical task. we are running a training company having the slogan “Learn-Practice-Lead”. We run our classes with limited students but ensure professional and career growth with long-term planning. We believe in actual work on a project to understand the customer needs and its business impact with proper governance on it. How we can use Technology Architecture to resolve this issue with MVP development with a low cost of operations?
We have trained 100+ candidates since 2018 in various domains being good people, they are supporting us in doing corporate social responsibility work. Running weekend meets up. Mentoring candidates. Planning a career with a backup plan in this volatile, uncertain, complex, and ambiguous (VUCA) World.
Join us today and take the first step towards unlocking your potential in the dynamic world of IT. We are committed to empowering you with the knowledge and expertise needed to thrive in the digital era. Choose KPS for IT training and skill development and embark on a journey to success!
Why Choose Us?
Experienced and Certified Instructors for Exceptional Learning-Our courses are led by highly skilled instructors with extensive industry experience and recognized certifications. They bring real-world knowledge and expertise to the classroom, ensuring you receive top-notch training.
Hands-on Practical Projects for Real-Life Expertise-At KPS, we believe in the power of learning by doing. Throughout our programs, you’ll engage in hands-on practical projects that simulate real-life scenarios. This approach hones your skills and prepares you to confidently tackle challenges in the IT field.
Embrace Flexibility in Your Learning Journey-Understanding that everyone’s schedule is unique, we offer flexible learning options. Whether you prefer the convenience of online courses or the traditional classroom setting, we’ve got you covered.
Unlock Exciting Opportunities with Job Placement Assistance-Your success is our priority. We provide dedicated job placement assistance to help you kickstart or advance your career in the IT industry. Our strong network of industry connections opens doors to exciting opportunities.
Elevate Your Career with Industry-Recognized Certifications-Upon completing our training programs, you’ll earn industry-recognized certifications that hold immense value in the job market. These certifications validate your skills and provide you with a competitive edge in your career journey.
Key Features of Our Training Services
Live Virtual Classes: Offer live virtual classes and webinars with industry experts to provide real-time learning opportunities, Q&A sessions, and networking possibilities.
Certifications and Badges: Offer industry-recognized certifications and badges upon course completion to add value to learners' resumes and showcase their expertise.
Live Projects and Internships: Collaborate with companies to provide learners with opportunities to work on real industry projects and internships, gaining practical experience.
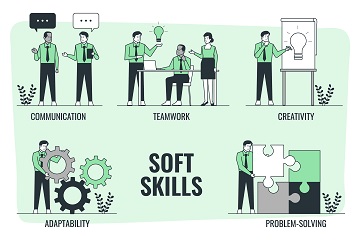
Soft Skills Training: Recognize the importance of soft skills and include training modules on communication, teamwork, and leadership to enhance the overall employability of learners.
Learning through Open-Source Contributions: Encourage learners to contribute to open-source projects, fostering real-world experience and a sense of community engagement.
What Our Students Say?
Atharv Mohol
January 31, 2024
Yeah the thing your searching for is here I have got great attention from knowledge power solutions to make my weakness my strength and successfully got a job and working there for 2 years
Vikash Kumar
January 31, 2024
I am doing internship in Spring Boot, Rest API, Microservices, Spring Security, Spring Cloud, SQL Server, MySQL DB, Postgres SQL, Mongo DB, Oracle, DB2, and in front-end technologies like, Html, CSS, JavaScript, Angular, React, in Knowledge Power Solutions. KPS provided me, depth knowledge good skills to survive in IT companies. I got to learn API development in backend and that API in JSON format designed in many front-end technologies, Angular, React, JavaScript Ajax call.
Chirag Pandkar
November 22, 2023
I recently completed my training at Knowledge Power Solutions, and I am thrilled to share my positive experience. The institute provided me with valuable knowledge and skills that led to my placement in an IT company with a package of 5 LPA.
I highly recommend Knowledge Power Solutions to anyone seeking quality education and a promising career in IT. I am grateful for the opportunities this institute has provided me and am excited to embark on my professional journey with the skills I've gained here.
Thank you, Knowledge Power Solutions, for the outstanding support!
Rushikesh Dhole
July 12, 2023
Recently the knowledge power solution helps for my laundry inventory management the application's well-designed layout and clear instructions make it easy to understand and operate, minimizing the learning curve for our team members.
Akash Dalvatkar
December 26, 2022
I have completed AWS and Azure cloud computing course with practical approach. Now I am placed successfully as Systems Administrator with one of the renewed educational institutions i.e., INDSEARCH. Thanks for inspiring me to Learn-Practice-Leading in my career.
Sagar Manore
December 26, 2022
I have completed Full Stack Developer Course from here. Now I can do end to end application development own my own. to learn practical coding. I strongly recommend this IT Training Institute.
Ravindra Nagargoje
June 27, 2022
I have learnt software testing, API and database testing.
I also learn a lot of new things. Even if you have no prior IT experience, this is the best place to learn. I had an excellent experience with KPS.
Thanks a lot for this opportunity.
Vishal Karpe
June 21, 2022
Best educational institute in Pune for software career.
Now i am learning cloud computing technology from this institute.
Siddharth pawar
June 21, 2022
In KPS, i have developed many technical skills like Tableau, PowerBI,
Mysql, Mssql, Microsoft EXCEL, Business stats, Python, R Language.
Learn so many new things Best place to learn even if you are not from IT background. I got to learn many new skills and real life industry exposure and I got job, Currently working in AXA business services with package of 4.5 LPA. that was my really great experience.