Understanding Spark Architecture
Apache Spark is a distributed computing framework designed for big data processing. It is fast, easy to use, and supports various programming languages like Java, Scala, Python, and R. Spark’s architecture is designed to process data in parallel across a cluster, making it highly scalable and efficient for large-scale data analytics tasks.
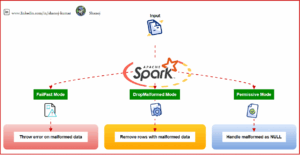
Key Components of Spark Architecture
-
Driver Program (Spark Driver):
- The driver is the heart of the Spark application. It is responsible for orchestrating the whole execution process of a Spark job.
- The driver:
- Translates user-defined transformations (like
map,filter, etc.) into a Directed Acyclic Graph (DAG) of stages. - Schedules tasks based on this DAG and monitors their execution.
- Maintains metadata about the application, including information on the cluster and available resources.
- Translates user-defined transformations (like
- The driver program communicates with the cluster manager to request resources and interacts with the executors to execute tasks.
-
Cluster Manager:
- The cluster manager is responsible for resource allocation in a distributed environment.
- There are three types of cluster managers Spark can work with:
- Standalone: A simple cluster manager included with Spark.
- YARN: Used with Hadoop clusters for managing resources.
- Mesos: A general-purpose cluster manager.
- The cluster manager allocates resources (executors) to Spark applications as requested by the driver.
-
Executors:
- Executors are worker nodes in the cluster responsible for:
- Executing tasks on the data.
- Storing data in memory or disk for future use (caching).
- Reporting the status and results of tasks back to the driver.
- Each Spark application gets its own set of executors.
- Executors are worker nodes in the cluster responsible for:
-
Tasks:
- A task is the smallest unit of execution in Spark. Each stage of a job is divided into multiple tasks, which are distributed across the executors.
- Tasks are run in parallel to perform transformations on different partitions of the data.
-
SparkSession:
- SparkSession is the entry point to interact with the underlying Spark functionalities. It allows you to create DataFrames and work with structured data.
- It replaces the older SparkContext and provides a unified abstraction for working with different Spark components like SQL, streaming, and machine learning.
-
DAG Scheduler:
- Spark uses a Directed Acyclic Graph (DAG) to represent the sequence of operations to be performed on the data.
- The DAG scheduler divides the job into stages. Each stage consists of multiple tasks that can be executed in parallel.
- The DAG scheduler optimizes the execution of the job by minimizing data shuffling and other costly operations.
-
Tasks Scheduler:
- The task scheduler assigns tasks to the executors and monitors their execution.
- It handles task failures, retries tasks if they fail, and ensures fault tolerance by keeping track of data lineage (through the RDDs).
-
RDD (Resilient Distributed Dataset):
- RDDs are the fundamental data structure in Spark, representing a distributed collection of data across the cluster.
- RDDs are immutable and are lazily evaluated, meaning transformations on RDDs are only executed when an action (like
collect,count, etc.) is called. - RDDs also have built-in fault tolerance using lineage: if a partition of an RDD is lost, Spark can recompute it from the original data.
How Spark Processes Data: Execution Flow
-
User Program:
- The user submits a Spark application using SparkSession (or SparkContext). The application contains a series of transformations and actions on data (such as reading a file, applying filters, and calculating results).
-
DAG Creation:
- The driver program parses the user’s transformations and creates a DAG of stages. Each stage contains multiple tasks that can be run in parallel.
-
Job Submission:
- The DAG scheduler submits the job to the task scheduler, which breaks it down into tasks and sends them to executors for execution.
-
Task Execution:
- Each executor runs tasks, typically applying transformations to partitions of data. Data is stored in memory (if caching is used) or disk for reuse.
-
Result Return:
- The results of tasks are returned to the driver, which aggregates the results (if necessary) and produces the final output.
Key Concepts in Spark
-
Transformations vs. Actions:
- Transformations (like
map,filter,join, etc.) are lazy operations that define a new RDD from an existing one. They are not executed immediately; instead, Spark builds a DAG of transformations. - Actions (like
collect,count,saveAsTextFile, etc.) trigger the execution of the DAG and return results to the driver or save them to an external storage system.
- Transformations (like
-
In-Memory Processing:
- One of Spark’s primary advantages is its ability to perform in-memory computation. By caching intermediate data in memory (using
cache()orpersist()), Spark can drastically speed up iterative algorithms like those in machine learning.
- One of Spark’s primary advantages is its ability to perform in-memory computation. By caching intermediate data in memory (using
-
Fault Tolerance:
- Spark achieves fault tolerance using RDDs. If part of the data is lost, Spark can recompute the lost data using its lineage (the series of transformations that produced the data).
-
Data Partitioning:
- Spark automatically partitions RDDs into chunks that can be processed in parallel. Users can also control the number of partitions to optimize performance based on data size and available resources.
Advantages of Spark Architecture
-
Scalability:
- Spark can scale horizontally by adding more nodes to the cluster, enabling it to process massive datasets distributed across many machines.
-
High Performance:
- By leveraging in-memory processing, Spark outperforms traditional disk-based frameworks like Hadoop MapReduce for iterative jobs.
-
Fault Tolerance:
- Spark ensures that even if part of the computation fails, it can recover and recompute the lost data without having to restart the entire process.
-
Unified Engine:
- Spark provides a unified engine for batch processing, real-time streaming (Spark Streaming), interactive queries (Spark SQL), machine learning (MLlib), and graph processing (GraphX).
Use Cases
-
Batch Processing:
- Processing large datasets in batch mode, such as data aggregation or ETL (Extract, Transform, Load) processes.
-
Stream Processing:
- Real-time data processing and analytics using Spark Streaming to handle event data streams, like analyzing real-time logs or monitoring sensor data.
-
Machine Learning:
- Using Spark’s MLlib library for building and training scalable machine learning models on large datasets.
-
Interactive Analytics:
- Spark SQL allows interactive querying of data stored in distributed file systems or databases, enabling users to run complex SQL queries.
Conclusion
Apache Spark’s architecture is designed for distributed, scalable, and fault-tolerant processing of large datasets. Its ability to handle both batch and real-time data processing, combined with support for various analytics tasks, makes Spark a powerful tool for modern data engineering, analytics, and machine learning.
