In the modern digital landscape, businesses and organizations generate massive amounts of data daily. However, data by itself is not inherently valuable until it is processed, analyzed, and transformed into actionable insights. This is where data engineering plays a critical role. Data engineering involves designing, building, and maintaining systems and infrastructure that allow data to be efficiently collected, stored, and processed for analysis. These systems form the backbone of data-driven decision-making in today’s enterprises.
1. Role of Data Engineering
Data engineers play a pivotal role in preparing and managing data for analysis, enabling data scientists and analysts to derive insights efficiently. Their responsibilities include:
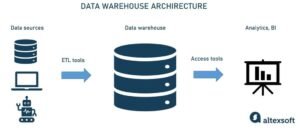
- Data Pipeline Development: Creating workflows that automate the extraction, transformation, and loading (ETL) of data from various sources to data warehouses or lakes.
- Data Quality Management: Ensuring the accuracy and integrity of data throughout its lifecycle.
- Data Modeling: Designing data structures and schemas to optimize performance and storage efficiency.
- Collaboration: Working closely with data scientists, business analysts, and stakeholders to understand data needs and provide reliable datasets for analysis.
Overview of Data Engineering in Modern Architecture
- In modern architectures, data engineering focuses on creating robust, scalable pipelines that handle various types of data (structured, unstructured, semi-structured) and deliver it to storage or analytics systems. Historically, data processing was primarily done in batch mode, where data was collected, processed, and analyzed in large chunks. Today, however, the landscape has evolved to also include real-time or streaming processing, where data is processed as soon as it’s generated.Modern data engineering architectures often feature:
- Data Warehouses for structured data.
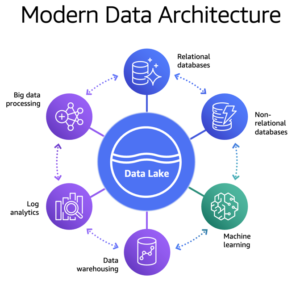
- Data Lakes for handling both structured and unstructured data.
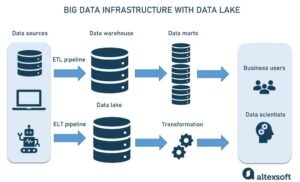
- Cloud platforms for scalable infrastructure (e.g., AWS, Google Cloud, Azure).
- Data pipelines to automate the movement and transformation of data.
2. Modern Architectural Components
This diagram depicts a high-level overview of a typical modern data architecture where data is ingested from multiple sources, processed using both batch and real-time tools, and stored in either a data lake or data warehouse for analysis