Key Technologies and Trends in Data Engineering
Modern data engineering uses a variety of tools and techniques to ensure data pipelines are scalable, efficient, and reliable. Let’s explore some key trends and technologies shaping the field:
- ETL (Extract, Transform, Load)
ETL is the traditional process where data is extracted from a source, transformed to meet the system’s requirements (e.g., cleaning, reformatting), and then loaded into a data warehouse.

Example Workflow:
[ Extract (Source Systems) ] –> [ Transform (Clean, Aggregate) ] –> [ Load (Data Warehouse) ]
Tools: Talend, Informatica, Apache Nifi
- ELT (Extract, Load, Transform)
In ELT, data is extracted and loaded directly into a data warehouse or data lake, and transformations are performed afterward. This leverages the power of modern cloud computing platforms to handle large-scale data transformations within the system.
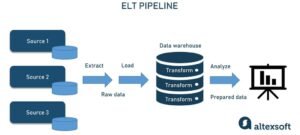
Example Workflow:
[ Extract (Source Systems) ] –> [ Load (Data Lake) ] –> [ Transform (Inside Warehouse) ]
Tools: Snowflake, Google BigQuery, Databricks
- Batch Processing
Batch processing deals with processing large datasets in one go. It’s ideal for use cases where immediate insights are not necessary but large amounts of data need to be processed at scheduled intervals.
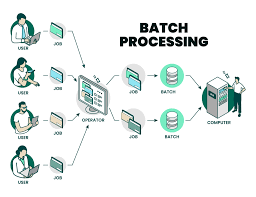
Example Workflow:
[ Data Sources ] –> [ Scheduled Processing (Spark, Hadoop) ] –> [ Data Storage ]
Tools: Apache Hadoop, Apache Spark, AWS Batch
- Streaming Processing
Streaming processing allows data to be processed in real-time as it is generated. This is useful for scenarios like real-time fraud detection or monitoring IoT devices.
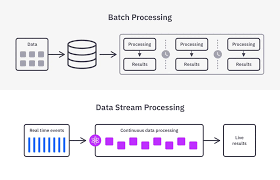
Example Workflow:
[ Streaming Data Source (IoT, Kafka) ] –> [ Real-Time Processing (Flink, Kinesis) ] –> [ Storage ]
Tools: Apache Kafka, Apache Flink, AWS Kinesis
