Apache Spark provides three main abstractions for working with data: RDDs (Resilient Distributed Datasets), DataFrames, and Datasets. Each abstraction has different use cases, benefits, and trade-offs.
Here’s a comparison between RDDs, DataFrames, and Datasets to understand the key differences:
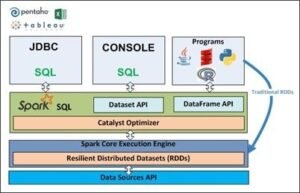
1. RDD (Resilient Distributed Dataset)
Overview:
- RDD is the fundamental data structure in Spark.
- It is an immutable, distributed collection of objects.
- RDDs are fault-tolerant, meaning they can automatically recover from node failures.
- They are the lowest level of abstraction in Spark and provide the most control over data distribution and computation.
Characteristics:
- Immutable: Once created, the data in an RDD cannot be modified. However, transformations (like
map,filter, etc.) produce new RDDs. - Distributed: RDDs are divided into partitions, which are distributed across the nodes in a cluster.
- Fault-Tolerant: RDDs automatically recover lost data by recomputing transformations from the source data.
- Lazy Evaluation: Transformations on RDDs are lazily evaluated, meaning the actual computation is not performed until an action (such as
collect()orcount()) is triggered.
API:
- RDDs provide two types of operations: transformations (like
map,filter,flatMap) and actions (likecollect,reduce,count).
Use Cases:
- When fine-grained control over the computation is required.
- When working with low-level transformations, such as custom partitioning.
- Suitable for unstructured data like text, logs, or raw binary data.
Example:
python
rdd = spark.sparkContext.parallelize([1, 2, 3, 4])
rdd_filtered = rdd.filter(lambda x: x % 2 == 0)
print(rdd_filtered.collect()) # Output: [2, 4]
Pros:
- Fine control over data distribution and parallel processing.
- Can handle any type of data (unstructured, semi-structured, or structured).
Cons:
- No built-in optimization, as RDDs don’t have a schema or advanced query planning.
- Manual optimization and tuning required (e.g., caching, partitioning).
2. DataFrames
Overview:
- A DataFrame is a distributed collection of data organized into named columns, similar to a table in a relational database or a dataframe in R or Python’s pandas.
- DataFrames have a schema, making it easier to work with structured and semi-structured data.
- They are optimized for performance through Catalyst Optimizer (SQL query optimization engine) and Tungsten execution engine.
Characteristics:
- Schema-Aware: DataFrames have a schema that defines the structure of the data (column names, data types, etc.).
- Optimized Execution: Spark’s Catalyst Optimizer and Tungsten engine automatically optimize the execution of DataFrame operations.
- SQL-like Operations: DataFrames support SQL operations (
select,filter,groupBy, etc.) and can be queried using Spark SQL.
API:
- DataFrames provide high-level APIs for transformation and analysis in languages like Python, Scala, Java, and R.
- DataFrames are lazy like RDDs, and transformations are only executed when an action is called.
Use Cases:
- When working with structured or semi-structured data.
- When you need SQL-like operations or want to run SQL queries directly on data.
- Ideal for analytics, aggregations, and queries that require optimization.
Example:
python
df = spark.read.csv("data.csv", header=True, inferSchema=True)
df_filtered = df.filter(df['age'] > 30)
df_filtered.show()
Pros:
- Higher performance due to internal optimizations.
- Easier to use with structured data.
- Can execute both SQL queries and DataFrame transformations.
Cons:
- Less control over low-level data manipulation compared to RDDs.
3. Dataset
Overview:
- Dataset is a combination of RDDs and DataFrames, providing the best of both worlds.
- Like DataFrames, Datasets are distributed collections of data with a schema.
- Unlike DataFrames, Datasets are strongly typed (only available in Scala and Java).
Characteristics:
- Type-Safe: Provides compile-time type safety, ensuring that errors in your code are caught at compile time (Scala/Java).
- Optimized Execution: Like DataFrames, Datasets are optimized using the Catalyst Optimizer and Tungsten engine.
- Immutable and Distributed: Similar to RDDs, Datasets are distributed across the cluster, and they are immutable.
API:
- In Scala and Java, Datasets provide an API that supports both object-oriented programming (OOP) and functional transformations (map, flatMap, filter, etc.).
- Datasets are typed versions of DataFrames in Scala/Java but are not available in Python.
Use Cases:
- When working with structured or semi-structured data in a strongly-typed environment (Scala/Java).
- Suitable for working with object-oriented programming paradigms.
- Ideal when performance is critical but type safety is also important.
Example (Scala):
scala
case class Person(name: String, age: Int)
val ds = Seq(Person("Alice", 29), Person("Bob", 35)).toDS()
val ds_filtered = ds.filter(_.age > 30)
ds_filtered.show()
Pros:
- Type-safe, enabling compile-time error checking.
- Provides the same optimizations as DataFrames while offering more control.
- Works well with object-oriented code and functional transformations.
Cons:
- Available only in Scala and Java.
- May require more verbosity compared to DataFrames for simple transformations.
Comparison Summary:
| Feature | RDD | DataFrame | Dataset |
|---|---|---|---|
| Abstraction Level | Low-level (primitive operations) | High-level (with schema) | High-level (with schema + type safety) |
| Type Safety | No | No | Yes (Scala/Java) |
| Schema | No | Yes (defined schema) | Yes (defined schema + compile-time) |
| Optimizations | No (manual optimization) | Yes (via Catalyst & Tungsten) | Yes (via Catalyst & Tungsten) |
| Data Structure | Distributed collection of objects | Distributed collection of rows | Distributed collection of typed objects |
| Performance | Lower (no optimizations) | Higher (optimized via Catalyst and Tungsten) | Higher (optimized via Catalyst and Tungsten) |
| Ease of Use | Complex (requires more coding effort) | Easy (SQL-like API, simple operations) | Intermediate (requires OOP knowledge) |
| Language Support | Python, Scala, Java | Python, Scala, Java, R | Scala, Java (Python doesn’t support Dataset API) |
| Use Cases | Unstructured data, custom transformations | Structured/semi-structured data, SQL queries | Type-safe operations in Scala/Java |
Key Takeaways:
- RDD: Use when you need low-level control and are working with unstructured data or custom transformations, but be aware of the need for manual optimizations.
- DataFrame: Ideal for structured and semi-structured data, offering higher-level APIs and optimizations. It is easy to use and integrates well with SQL queries.
- Dataset: Provides the benefits of both RDDs and DataFrames but with compile-time type safety (in Scala and Java). It is a good fit when working in a type-safe environment with structured data.
In general, DataFrames and Datasets are preferred over RDDs for most tasks due to better performance, ease of use, and built-in optimizations.
4o
