Cloud-Based Data Storage: AWS S3 and Azure Blob Storage
Cloud storage provides scalable and cost-effective solutions for storing data with global accessibility and built-in redundancy.
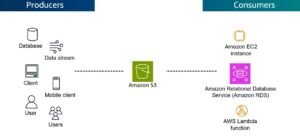
- Amazon S3 (Simple Storage Service):
- Object-based storage service designed for scalability, security, and durability.
- Ideal for storing any type of data: text, images, videos, backups, etc.
- Key Features:
- Pay-as-you-go pricing: Only pay for what you use.
- Integrated with AWS services: Easy integration for data pipelines.
- Lifecycle policies: Automatically transition data to cheaper storage tiers or delete after a set time.

- Azure Blob Storage:
- Microsoft’s object storage solution for storing unstructured data.
- Designed for large-scale storage needs with access via HTTP/HTTPS.
- Key Features:
- Tiers of storage: Hot, cool, and archive tiers for cost-effective data management.
- Scalability and high availability: Built-in redundancy across regions.
- Security: Role-based access control (RBAC) and encryption options.

Use Cases:
- Storing backups, large datasets, multimedia files, and log data; perfect for use with data pipelines or ETL processes.
