
Activity: Real-World Data Pipeline Use Case – E-Commerce Platform
Let’s discuss a real-world use case to understand how data pipelines work in practice.
Problem Statement:
An e-commerce company wants to process user activity data (clicks, searches, purchases) in real-time to provide personalized product recommendations and analyze user behaviour.
Data Sources:
- Website Logs: Captures user activity on the e-commerce platform.
- Transactional Data: Stores information related to purchases and customer details.
- External APIs: Fetch data such as product ratings and reviews.
Pipeline Overview:

- Data Collection: User activity logs and transaction records are collected from web servers and databases.
- Data Ingestion:
- Streaming data (user clicks) is ingested using Apache Kafka for real-time processing.
- Batch data (transactional records) is ingested into AWS S3 for further processing.
- Data Processing:
- Real-time processing with Apache Flink to power personalized recommendations.
- Batch processing with Apache Spark to generate daily sales reports and customer insights.
- Data Storage:
- Real-time processed data is stored in Redis for fast access by the recommendation engine.
- Processed batch data is stored in Snowflake for business analysis.
- Data Analysis:
- Business analysts use Tableau dashboards for insights into sales performance and customer behavior.
- Machine learning models analyze user behavior to improve recommendation algorithms.
Diagram: E-Commerce Data Pipeline
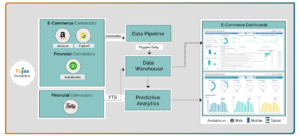
This pipeline showcases how data engineering integrates batch and real-time processing to power key business use cases, such as personalization and reporting.
- Conclusion
Data engineering is an essential component of modern data-driven organizations. By building robust pipelines, data engineers ensure that raw data is efficiently transformed into valuable insights. The rise of cloud computing, scalable data lakes, and real-time processing frameworks has transformed how data is collected, stored, and analyzed. Understanding the key technologies, trends, and real-world applications of data engineering will help you create scalable, efficient systems that power data-driven decision-making.
Whether working with batch or streaming pipelines, the core principles remain the same: managing data throughout its lifecycle and ensuring it’s ready for analysis or machine learning.
